The importance of sales promotions as the drivers of consumer behaviour has grown during recent decades and a significant proportion of all retail sales are made as a result. The increased usage of digital marketing with personalised, time-dependent offers has only served to amplify this phenomenon. It is therefore inevitable that the management and forecasting of promotional activities must keep up apace with this trend. The challenge lies in that retailers’ traditional category-based models for forecasting and planning promotions are no longer sophisticated enough to cope.
Traditionally, forecasting for promotions has been based on categorising products into distinct groups based on their characteristics: ie what price reduction the promotion had, what kind of in-store display was used and what kind of marketing activities were executed during the promotion. The forecast for the upcoming promotion would then be based on the average sales performance of the group of promotions with similar characteristics.
While this method is sophisticated enough in many ways, it also has significant drawbacks which are mainly based on assumed data correlation, in itself necessary for the model to work.
Category-based modelling works on identifying groupings and responses around product categories or location: bread can have a different response to promotional activities than confectionery, and small stores can have different responses than large stores. Existing best in class promotion forecasting solutions also work on intelligently searching for an appropriate grouping when there is no exactly matching data available. For example, a lack of historical data for similar promotions with the same characteristics for a certain SKU-store combination, or a statistically insignificant number of matching promotions.
However, the shortcomings with this forecasting model lie in the way categorisation has to be used to statistically generalise what are actually highly specific and non-linear correlations in the data.
- The limitations of categorising: Let’s say the price reductions of promotions are categorised into categories of “0-20%”, “20-40%” and “over 40%”. This leads to a situation where the forecasted effects of price reductions of 21% and 39% are equal, even though they probably should be closer to the effects of categories “0-20%” and “over 40%” respectively. However, defining more fine-grained categories reduces the reliability and accuracy of the promotion forecasts, as the amount of data behind each distinct category is reduced. On the other hand, adding manual rules unnecessarily increases the complexity of a retailer’s promotion forecasting setup and makes it a lot harder to manage.
- Utilisation of the data: Using only exactly matching reference promotions (e.g. same price reduction category, same in-store display and same marketing activities) as input in the promotion forecasting model neglects a significant amount of data that partially matches the upcoming promotion (e.g. different price reduction category, but same in-store display and same marketing activities) and that would be valuable information for promotion forecasting.
- Big data isn’t always meaningful data: Not too seldom when going through the promotion master data there are promotions that belong to, for example, more than 10 categories which all are ‘required’ to be utilised in forecasting: we live in the big data era after all. However, big data doesn’t always mean meaningful data: It can be that only three or four of those categories contribute to sales performance, or that the 10 categories could be combined into smaller numbers of categories for forecasting purposes. With the category-based approach it’s not instantly clear which categories are relevant – and which irrelevant – in terms of forecasting.
- Simultaneous promotions with different categorisations: Promotion data can include promotions that overlap with each other which makes it difficult to say which part of the promotion performance is achieved by which promotion and category combination.
So how can retailers achieve more sophisticated and accurate models for forecasting for promotions?
Causal modeling is a methodology that can overcome some of these drawbacks. These methods are designed to extract the cause-effect relationships between certain group of variables, ie ‘explaining’ the data as well as possible with given parameters. So, when forecasting promotional sales using causal methods, instead of asking “How have similar promotions performed in the past?”, one could ask “What’s the effect of a 24% price discount on demand; what’s the effect of a special display; or both of those combined?”.
In more detail, causal methods tackle the identified drawbacks by:
-
- Utilising continuous variables instead of category variables: Establishing a continuous relationship between e.g. the price decrease and demand allows a retailer to estimate more precisely what’s the discount’s effect on demand.
- Separating the effects from one another: Causal methods can shed light on the estimated effects of individual variables and combinations of those variables, and thus drawing insights from the whole data set, not only from exactly similar promotions.
- Separating meaningful data from the noise: Examining the results of causal methods, and automating the analysis of results allows a retailer to determine which variables have a significant impact on the promotional sales, which don’t, and use that information in forecasting.
Increased accuracy
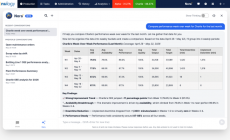
Utilising these advanced models in promotion forecasting and benchmarking them against the previous Historical Averages model has revealed significant benefits: forecast error decreases up to 15 percentage points on average, and forecasts are substantially stabilised, meaning that the number of high error peaks decreases significantly.
Better planning
The added value isn’t only about forecasting more accurately – the promotion planning process can also be improved by using causal methods: knowing the effect of individual promotion characteristics to the demand of each individual SKU-store combination allows planning to be done in a more refined way by concentrating the promotional activities to where it matters the most. For example, there’s no point in adding heavy discounts or marketing activities to SKUs that respond poorly to price decreases or advertising. Turning that setting upside down, it’s possible to optimise the price decrease and promotional activities to meet certain sales targets – e.g. in case of markdown sales, where the target is to sell out the existing inventory. These activities help to increase the efficiency of the promotion planning and managing process, and ultimately to increase profit.
Best practices for forecasting promotions
When implementing a promotion forecasting process the golden rule of ‘garbage in, garbage out’ applies. When utilising more sophisticated promotion forecasting models, it is even more true.
A good first step is therefore to ensure that the promotion master data is in good shape: promotion prices are correct and promotion characteristics are thoroughly and systematically set up. This isn’t as self-evident as it sounds: Manual typos are quite typical in promotion master data, e.g. a promotion price of 49.9 instead of 4.99 and tv marketing instead of tv-marketing. Cleaning the master data really pays off when automating the promotion forecasting process.
The second step is to establish a process where causal promotion forecasting models are estimated on multiple levels and the most appropriate of them is chosen. The acceptance criteria should consider at least the reliability of the estimates as well as the granularity of the data: usually the lower the level of the estimation, the better, meaning for example that in the typical retail setting, the SKU-store level yields the most accurate results. The promotion forecasting process should also be automated; nobody wants to spend countless hours going through the different models on different levels for possibly millions of SKU-store combinations.
Once the promotion forecasting process has been satisfyingly implemented, the results can also be extended beyond forecasting – start planning the promotional activities operations based on the results of the automated analysis.
Conclusion
By breaking down the promotional sales into price component, user-defined promotional activity components and non-promotional sales components, and enabling the analysis and forecasting of the impact of each of the components on SKU-store level, causal modeling has proven to be significantly more accurate than traditional category-based promotion forecasting, increasing a retailer’s margins and profitability levels.
For promotions forecasting to move in line with today’s rapid pace of promotional activity, it’s time to move away from historical, aggregated data models and utitlise the power of big data analytics to its full advantage.